SURVEILLANCE OF SOIL FERTILITY CONDITION
Soil condition classification
Soil
condition (F) of a watershed, at a hypothetical
point in time, can be mathematically represented as:
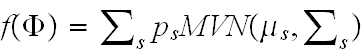
where p is the proportion
of soil sampling units in condition (s), which we assume may be ranked
on an ordinal scale from, for example, good to poor in s classes, and
MVN(ms,Ss) are the respective multivariate normal probability densities
of measurement endpoints (or condition indicators), with mean vectors
ms and covariance matrices Ss.
We used ten commonly used agronomic soil fertility indicators to estimate
parameters in the above equation for three soil classes: 'good', 'average',
and 'poor') for a subset of n=801 soil library samples originating from
267 plots in the Kenya Lake Victoria Basin. that are widely used for tropical
soils. The soil fertility indicators used were ph, clay, silt, ECEC, Ca,
Mg, K, P, organic C, and mineralizable N potential (laboratory methods).
The model was fitted using the Expectation-Maximization (EM) algorithm
(details in Ripley, 1996 and Edwards, 2001) as implemented in the graphical
modeling software MIM® v. 3.5 (Edwards, 2001). Where necessary, Box-Cox
transformations (Box and Cox, 1964) were applied prior to analysis to
obtain approximately multivariate normally distributed values.
The posterior probability for a new observation (x = vector of soil properties)
belonging to a given condition class (s), is calculated as:
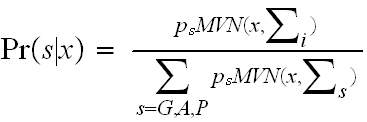
for which ps
represents the respective proportions of the three condition classes.
Back to top 
|
